

近日,MRACLE团队在IEEE/CVF计算机视觉与模式识别会议(CVPR 2025)上发表了题为《DH-Set: Improving Vision-Language Alignment with Diverse and Hybrid Set-Embeddings Learning》的最新研究成果。该工作张坤为第一作者,周少华教授为通讯作者,研究单位包括中国科学技术大学苏州高等研究院、生物医学工程学院以及中国科学院计算技术研究所智能信息处理重点实验室等。
视觉-语言(Vision-Language, VL)对齐是人工智能领域的一项基础且富有挑战性的任务,其核心目标是让机器能够理解图像和文本之间的语义关联 。然而,数据中固有的语义模糊性(Semantic Ambiguity)为这一任务带来了巨大困难 。例如,文本“苹果”既可以指代一种水果,也可以指代一个科技品牌,而图像中的苹果也形态各异 。传统的VL对齐方法通常为每个输入学习一个单一的嵌入向量,难以有效处理这种“一词多义”或“一物多态”的现象 。
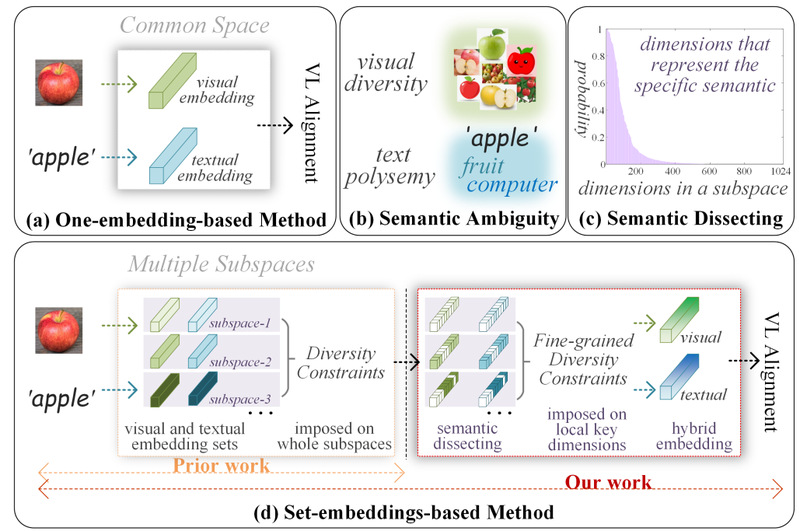
为了解决语义模糊性问题,学术界有工作提出将单个输入编码为一个“嵌入集合”(Set-of-Embeddings),通过学习多个子空间来捕捉数据的多样化语义 。尽管这一方向取得了良好效果,但现有方法仍存在两个主要缺陷:首先,它们对整个嵌入子空间施加多样性约束,忽略了特定语义主要由子空间内的部分“关键维度”所表达这一特性,可能因此损害多样性学习的精确性 ;其次,在推理阶段需要处理多个嵌入,这极大地增加了计算和存储开销,限制了方法的应用效率 。
针对上述挑战,研究团队创新性地提出了一个高效且强大的多样化混合集合嵌入学习框架(DH-Set)。该框架的核心贡献在于三个方面:
1)设计了一种新颖的语义重要性剖析方法,能够精准识别并聚焦于表达特定语义的“关键局部维度”;
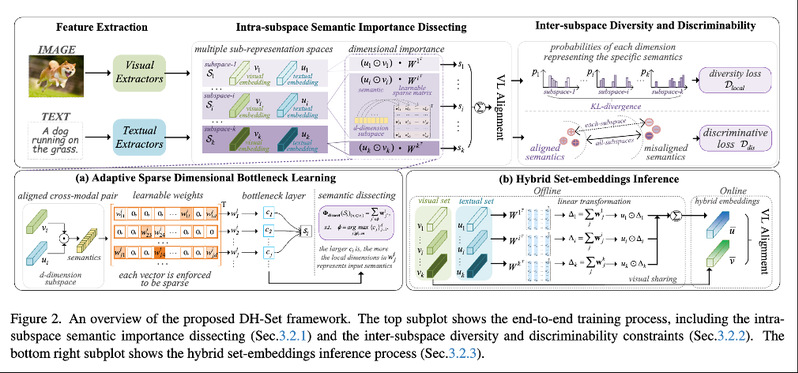
2)基于此,该方法不仅能够施加更细粒度的多样性约束,从而提升多样化嵌入学习的准确性,还能在推理时将所有子空间的“关键维度”融合成一个单一的混合嵌入,极大地提升了模型的效率 ;
3)最终实现了在推理阶段兼顾高效性与准确性的统一,将计算与存储复杂度降低了k≥3倍。在多个标准测试集上的实验结果表明,DH-Set框架性能卓越,相较于当前最优方法取得了2.3%至14.7%的rSum性能提升,充分证明了其先进性。
