

MIRACLE课题组在医学影像视觉基础模型研究方面取得进展
近日,中国科学技术大学苏州高等研究院医学影像智能与机器人研究中心(MIRACLE)联合上海交通大学,提出了名为MambaMIM的通用3D视觉预训练框架,聚焦于状态空间模型在长序列3D视觉建模中的应用。该工作突破了当前掩蔽建模方法中对图像掩码因果建模能力的局限,首次引入基于空间状态插值策略(TOKI)的通用预训练框架,显著增强状态空间模型处理长程依赖信息的能力。该成果以“MambaMIM: Pre-training Mamba with State Space Token Interpolation and its Application to Medical Image Segmentation”为题发表在国际顶级学术期刊Medical Image Analysis(影响因子10.7)。医学影像智能与机器人研究中心主任周少华教授和上海交通大学刘伟副教授为共同通讯作者,中国科学技术大学博士生汤丰赫为第一作者,上海交通大学博士生年炳坤和中国科学技术大学博士生李英泰为共同第一作者。

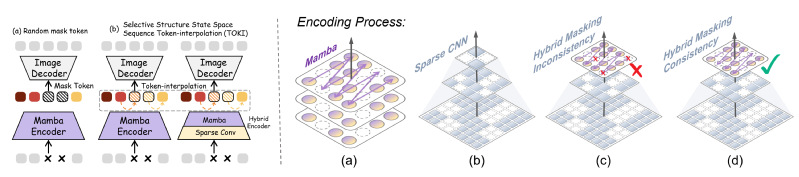
图一:空间状态插值(左)和掩码一致性(右)
近期,状态空间模型展现出高效的长序列建模能力,尤其在处理 3D 医学成像中的长序列视觉任务方面表现出色。然而,传统自监督学习策略普遍采用随机初始化的掩码令牌用于重建,忽略了序列间的因果关系建模,限制了状态空间模型的进一步发展。为应对这一问题,MambaMIM提出选择性结构状态空间序列插值(TOKI)策略,在状态空间上下文中进行掩码令牌插值,用于学习掩码序列状态空间的上下文因果关系。针对不同网络架构在掩码位置选择上的一致性问题,MambaMIM引入了一种自底向上的掩码建模策略,有效保证了跨架构、跨尺度的掩码一致性。此外,该框架设计了层级级联解码器,提升模型的多尺度表征学习能力。MambaMIM在大规模3D医学数据集上进行预训练,并在8个下游公共医学图像分割基准上(包括CT腹部器官,肿瘤和脑部MRI)中进行大量对比实验和性能评估,MambaMIM获得了最佳的分割性能。
图二:MambaMIM预训练框架图
文章链接:https://arxiv.org/pdf/2408.08070
